Python asyncio 异步协程 I/O
asyncio 是 Python 的一个内置库,主要用于编写单线程并发代码,通过协程实现异步 I/O 操作。它在 Python 3.4 版本中引入,提供了基于事件循环的并发模型,本文介绍了如何使用 Python asyncio,以及举出几个常见的应用场景
基本概念 阻塞与非阻塞 阻塞状态指程序未得到所需计算资源时被挂起的状态。程序在等待某个操作完成期间,自身无法继续干别的事情,则称该程序在该操作上是阻塞的。 常见的阻塞形式有:网络 I/O 阻塞、磁盘 I/O 阻塞、用户输入阻塞等。阻塞是无处不在的,包括 CPU 切换上下文时,所有的进程都无法真正干事情,它们也会被阻塞。如果是多核 CPU 则正在执行上下文切换操作的核不可被利用。
程序在等待某操作过程中,自身不被阻塞,可以继续运行干别的事情,则称该程序在该操作上是非阻塞的。 非阻塞并不是在任何程序级别、任何情况下都可以存在的。 仅当程序封装的级别可以囊括独立的子程序单元时,它才可能存在非阻塞状态。 非阻塞的存在是因为阻塞存在,正因为某个操作阻塞导致的耗时与效率低下,我们才要把它变成非阻塞的。
同步和异步 同步就是指一个进程在执行某个请求的时候,若该请求需要一段时间才能返回信息(例如网络请求的响应),那么这个进程将会一直等待下去,直到收到返回信息才继续执行下去; 异步是指进程不需要一直等下去,而是继续执行下面的操作,不管其他进程的状态。 当有消息返回时系统会通知进程进行处理,这样可以提高执行的效率。
协程 协程,英文叫做 Coroutine,又称微线程,纤程,协程是一种用户态的轻量级线程。 协程拥有自己的寄存器上下文和栈。协程调度切换时,将寄存器上下文和栈保存到其他地方,在切回来的时候,恢复先前保存的寄存器上下文和栈。因此协程能保留上一次调用时的状态,即所有局部状态的一个特定组合,每次过程重入时,就相当于进入上一次调用的状态。 协程本质上是个单进程,协程相对于多进程来说,无需线程上下文切换的开销,无需原子操作锁定及同步的开销,编程模型也非常简单。 我们可以使用协程来实现异步操作,比如在网络爬虫场景下,我们发出一个请求之后,需要等待一定的时间才能得到响应,但其实在这个等待过程中,程序可以干许多其他的事情,等到响应得到之后才切换回来继续处理,这样可以充分利用 CPU 和其他资源,这就是异步协程的优势。
异步协程用法 从 Python 3.4 开始,Python 中加入了协程的概念,但这个版本的协程还是以生成器对象为基础的,在 Python 3.5 则增加了 async/await,使得协程的实现更加方便。 Python 中使用协程最常用的库莫过于 asyncio,所以本文会以 asyncio 为基础来介绍协程的使用。 首先我们需要了解下面几个概念:
event loop:事件循环,相当于一个无限循环,asyncio 的核心,它提供了注册、取消和执行任务和回调的方法,我们可以把一些函数注册到这个事件循环上,当满足条件发生的时候,就会调用相应的协程函数。
coroutine:中文翻译叫协程,在 Python 中常指代为协程对象类型,我们可以将协程对象注册到时间循环中,它会被事件循环调用。我们可以使用 async 关键字来定义一个方法,这个方法在调用时不会立即被执行,而是返回一个协程对象。
task:任务,它是对协程对象的进一步封装,包含了任务的各个状态。
future:代表将来执行或没有执行的任务的结果,实际上和 task 没有本质区别。
async/await:async 定义一个协程,await 用来挂起阻塞方法的执行)。
导入 asyncio asyncio 是 Python 的内置库,无需安装
定义协程函数 使用async def定义的函数称为协程函数(coroutine function),调用函数时返回一个协程对象(coroutine object)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 import asyncioasync def main (): print ("Hello" ) await asyncio.sleep(1 ) print ("world" ) coro = main() print (coro)""" <coroutine object main at 0x0000026224530AC0> sys:1: RuntimeWarning: coroutine 'main' was never awaited RuntimeWarning: Enable tracemalloc to get the object allocation traceback """
要运行这个函数就要先进入 async 的模式,再把这个 coroutine object 变成一个 task
运行协程函数 运行协程函数的方法大致有三种,如下:
使用asyncio.run 使用asyncio.run()进入 async 模式,其参数为 coroutine object,这个函数会建立起 event loop,并且把参数 coroutine object 变成 event loop 里的第一个 task
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 import asyncioasync def main (): print ("Hello" ) await asyncio.sleep(1 ) print ("world" ) coro = main() asyncio.run(coro) """ Hello world """
等待一个协程 await 一个 coroutine object,会把 coroutine object 变成一个 task,再去运行
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 import asyncioimport timeasync def say_after (delay, what ): await asyncio.sleep(delay) print (what) async def main (): print (f"started at {time.strftime('%X' )} " ) await say_after(1 , 'hello' ) await say_after(2 , 'world' ) print (f"finished at {time.strftime('%X' )} " ) asyncio.run(main()) """ started at 16:30:38 hello world finished at 16:30:41 """
但这里发现共用时三秒,并没有并发地进行运行,使用asyncio.create_task()可以解决这个问题
使用create_task asyncio.create_task()函数用来并发运行作为 asyncio 任务地多个协程,我们修改以上示例,并发 运行两个 say_after 协程:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 import asyncioimport timeasync def say_after (delay, what ): await asyncio.sleep(delay) print (what) async def main (): task1 = asyncio.create_task(say_after(1 , 'hello' )) task2 = asyncio.create_task(say_after(2 , 'world' )) print (f"started at {time.strftime('%X' )} " ) await task1 await task2 print (f"finished at {time.strftime('%X' )} " ) asyncio.run(main()) """ started at 16:33:41 hello world finished at 16:33:43 """
可以看到比以前快了一秒
协程函数的返回值 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 import asyncioimport timeasync def say_after (delay, what ): await asyncio.sleep(delay) return f"{what} - {delay} " async def main (): task1 = asyncio.create_task(say_after(1 , 'hello' )) task2 = asyncio.create_task(say_after(2 , 'world' )) print (f"started at {time.strftime('%X' )} " ) ret1 = await task1 ret2 = await task2 print (ret1) print (ret2) print (f"finished at {time.strftime('%X' )} " ) asyncio.run(main()) """ started at 16:38:34 hello - 1 world - 2 finished at 16:38:36 """
这样就拿到了其函数的返回值
可等待的对象 如果一个对象可以在await语句中使用,那么它就是 可等待 对象。可等待对象有三种主要类型:协程 , 任务 和 Future
协程 正如上面举的例子,Python 协程属于可等待对象,因此可以在其他协程中被等待
任务 正如上面举的例子,当一个协程通过asyncio.create_task()等函数被封装为一个任务,该协程会被自动调度执行
对象 Futures 函数asyncio.gather()参数是若干个coroutine object、task甚至futures,它的返回值是一个futures,futures是可以被 await 的
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 import asyncioimport timeasync def say_after (delay, what ): await asyncio.sleep(delay) return f"{what} - {delay} " async def main (): task1 = asyncio.create_task(say_after(1 , 'hello' )) task2 = asyncio.create_task(say_after(2 , 'world' )) print (f"started at {time.strftime('%X' )} " ) ret = await asyncio.gather(task1, task2) print (ret) print (f"finished at {time.strftime('%X' )} " ) asyncio.run(main()) """ started at 16:51:18 ['hello - 1', 'world - 2'] finished at 16:51:20 """
在这里,asyncio.gather()会自动把 coroutine object 变成 task,也就是说我们可以不用手动建立 task:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 import asyncioimport timeasync def say_after (delay, what ): await asyncio.sleep(delay) return f"{what} - {delay} " async def main (): print (f"started at {time.strftime('%X' )} " ) ret = await asyncio.gather(say_after(1 , 'hello' ), say_after(2 , 'world' )) print (ret) print (f"finished at {time.strftime('%X' )} " ) asyncio.run(main()) """ started at 16:54:09 ['hello - 1', 'world - 2'] finished at 16:54:11 """
超时处理 asyncio.wait_for(async_func(), timeout=timeout),其中async_func()为协程函数,timeout为等待时长
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 import asyncioasync def eternity (): await asyncio.sleep(3600 ) print ('yay!' ) async def main (): try : await asyncio.wait_for(eternity(), timeout=1.0 ) except asyncio.TimeoutError: print ('timeout!' ) asyncio.run(main()) """ timeout! """
异步 I/O 使用 asyncio 进行网络 I/O 时要配合 httpx 库或者 aiohttp,进行文件 I/O 时要使用 aiofile
一个例子 在下面的例子里,async_1.php和async_2.php具有不同的响应时间 1 是三秒,2 是一秒,可以写出下面的脚本:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 import httpximport asyncioasync def request_get (num ): url = f"http://192.168.12.131/async_{num} .php" print (f"Running to get {url} " ) async with httpx.AsyncClient() as client : r = await client.get(url) print (f"{url} is down" ) return r.text async def main (): task1 = asyncio.create_task(request_get(1 )) task2 = asyncio.create_task(request_get(2 )) print (await task2) print (await task1) if __name__ == "__main__" : asyncio.run(main())
运行的结果:
1 2 3 4 5 6 Running to get http://192.168.12.131/async_1.php Running to get http://192.168.12.131/async_2.php http://192.168.12.131/async_2.php is down Hello, world! I am No.1 http://192.168.12.131/async_1.php is down Hello, world! I am No.3
可以看到请求会同时进行
一个更加实际的例子 现在有从 HTTP 日志文件里获得了一些 ip 地址,需要调用https://api.vore.top/api/IPdata?ip={ip}这个接口来获取这些 ip 地址的地址信息,ip 地址如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 194.187.176.146 194.187.176.55 62.162.152.178 83.97.73.87 179.60.147.13 172.105.128.11 5.182.209.121 104.152.52.196 170.64.166.144 67.217.57.54 45.33.80.243 118.123.105.92 218.55.66.14 60.217.75.70 202.102.32.130
假如使用同步来完成这个任务:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 import requestsdef get_ip_from_file (file_path ): with open (file_path, 'r' ) as f: ip = f.readlines() return [i.strip() for i in ip] def get_ip_location (ip ): url = f'https://api.vore.top/api/IPdata?ip={ip} ' response = requests.get(url) if response.status_code == 200 : location_data = "" data = response.json() for info in data['ipdata' ].values(): location_data += info else : location_data = "查询失败" return location_data def main (file_path="ip.txt" ): ips = get_ip_from_file(file_path) for ip in ips: location = get_ip_location(ip) print (location) if __name__ == "__main__" : main()
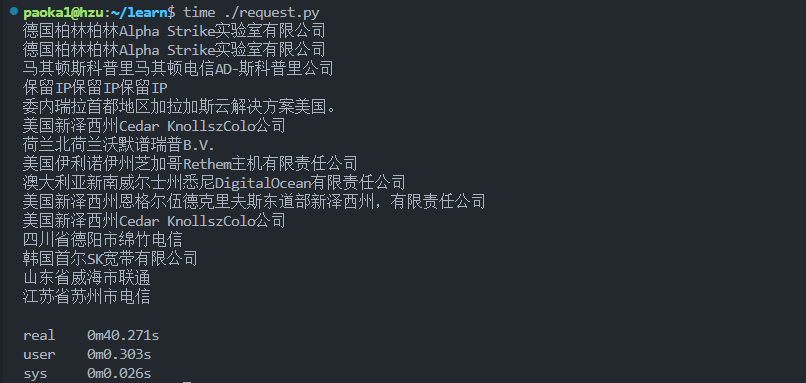
计算所需要的时间:
发现用时 40 秒,如果使用 asyncio 来完成:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 import httpximport asynciofrom pathlib import Pathdef get_ip_from_file (file_path ): with open (file_path, 'r' ) as f: ip = f.readlines() return [i.strip() for i in ip] async def get_ip_location (ip ): async with httpx.AsyncClient() as client: response = await client.get(f'https://api.vore.top/api/IPdata?ip={ip} ' ) if response.status_code == 200 : location_data = "" data = response.json() for info in data['ipdata' ].values(): location_data += info else : location_data = "查询失败" return location_data async def main (file_path=Path(__file__ ).parent / 'ip.txt' ): ips = get_ip_from_file(file_path) return await asyncio.gather(*[get_ip_location(ip) for ip in ips]) if __name__ == "__main__" : print (asyncio.run(main()))
发现这次只用时 5 秒,提升还是很大的(用时 5 秒与我的网络和系统性能有关,实际可以更短)
本文参考链接:
asyncio — 异步 I/O
【python】asyncio的理解与入门,搞不明白协程?看这个视频就够了。