Python 多线程的基本使用
基本知识 并发和并行 在单核 CPU 系统中,系统调度在某一时刻只能让一个线程运行,虽然这种调试机制有多种形式(大多数是时间片轮巡为主),但无论如何,要通过不断切换需要运行的线程让其运行的方式就叫并发。而在多核 CPU 系统中,可以让两个以上的线程同时运行,这种可以同时让两个以上线程同时运行的方式叫做并行。
同步和异步 同步就是指一个进程在执行某个请求的时候,若该请求需要一段时间才能返回信息(例如网络请求的响应),那么这个进程将会一直等待下去,直到收到返回信息才继续执行下去; 异步是指进程不需要一直等下去,而是继续执行下面的操作,不管其他进程的状态。 当有消息返回时系统会通知进程进行处理,这样可以提高执行的效率。
阻塞与非阻塞 阻塞状态指程序未得到所需计算资源时被挂起的状态。程序在等待某个操作完成期间,自身无法继续干别的事情,则称该程序在该操作上是阻塞的。 常见的阻塞形式有:网络 I/O 阻塞、磁盘 I/O 阻塞、用户输入阻塞等。阻塞是无处不在的,包括 CPU 切换上下文时,所有的进程都无法真正干事情,它们也会被阻塞。如果是多核 CPU 则正在执行上下文切换操作的核不可被利用。
程序在等待某操作过程中,自身不被阻塞,可以继续运行干别的事情,则称该程序在该操作上是非阻塞的。 非阻塞并不是在任何程序级别、任何情况下都可以存在的。 仅当程序封装的级别可以囊括独立的子程序单元时,它才可能存在非阻塞状态。 非阻塞的存在是因为阻塞存在,正因为某个操作阻塞导致的耗时与效率低下,我们才要把它变成非阻塞的。
多线程 多进程就是利用 CPU 的多核优势,在同一时间并行地执行多个任务,可以大大提高执行效率。
线程模块 使用内置模块 threading 来实现多线程
threading.currentThread():返回当前的线程变量threading.enumerate():返回一个包含正在运行的线程的列表threading.activeCount():返回正在运行的线程数量run():用以表示线程活动的方法start():启动线程活动join():等待至线程中止isAlive():返回线程是否活动的getName():返回线程名setName():设置线程名
创建线程 1 threading.Thread(group=None , target=None , name=None , args=(), kwargs=None , *,daemon=None )
group:指定所创建的线程隶属于哪个线程组
target:指定所创建的线程要调度的目标方法
args:以元组的方式,为 target 指定的方法传递参数
kwargs:以字典的方式,为 target 指定的方法传递参数
daemon:指定所创建的线程是否为后代线程
启动线程 使用thread.start()来启动线程
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 import threadingdef thread_job (): print ('This is a thread of %s' % threading.current_thread()) def main (): thread = threading.Thread(target=thread_job, name = "new_thread" ) thread.start() if __name__ == '__main__' : main() thread_job()
join() 的使用 join 的作用是让不同线程保持一样的状态
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 import threadingimport timedef job_1 (): print ("Job_1 start!" ) for i in range (0 , 10 ): time.sleep(0.1 ) print ("Now i is: %d" % i) print ("Job_1 down!" ) def job_2 (): print ("Job_2 start!" ) print ("Job_2 down!" ) def main (): theard_1 = threading.Thread(target = job_1, name = "tread_1" ) theard_2 = threading.Thread(target = job_2, name = "thread_2" ) theard_1.start() theard_2.start() print ("All down!\n" ) if __name__ == "__main__" : main() """ All down! Job_1 start! Job_2 start! Job_2 down! Now i is: 0 Now i is: 1 Now i is: 2 Now i is: 3 Now i is: 4 Now i is: 5 Now i is: 6 Now i is: 7 Now i is: 8 Now i is: 9 Job_1 down! """
可以看到,线程二的任务量小于线程一的任务量,但线程二没有等线程一完成后再往下进行,使用join可以让线程二等待线程一完成后再继续往下进行:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 import threadingimport timedef job_1 (): print ("Job_1 start!" ) for i in range (0 , 10 ): time.sleep(0.1 ) print ("Now i is: %d" % i) print ("Job_1 down!" ) def job_2 (): print ("Job_2 start!" ) print ("Job_2 down!" ) def main (): theard_1 = threading.Thread(target = job_1, name = "tread_1" ) theard_2 = threading.Thread(target = job_2, name = "thread_2" ) theard_1.start() theard_2.start() theard_1.join() print ("All down!\n" ) if __name__ == "__main__" : main() """ Job_1 start! Job_2 start! Job_2 down! Now i is: 0 Now i is: 1 Now i is: 2 Now i is: 3 Now i is: 4 Now i is: 5 Now i is: 6 Now i is: 7 Now i is: 8 Now i is: 9 Job_1 down! All down! """
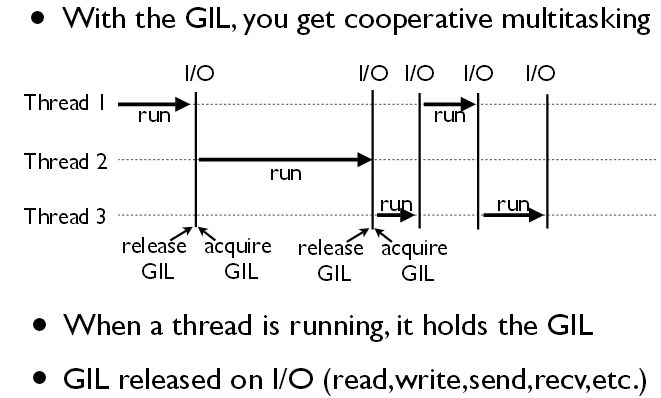
全局解释器锁(GIL) GIL 的全称是 Global Interpreter Lock(全局解释器锁),来源是 Python 设计之初的考虑,为了数据安全所做的决定。但这样的设计使得 Python 的多线程并不是真正意义上的多线程。GIL 是一个互斥锁(或锁),它只允许一个线程持有 Python 解释器的控制权即某个线程想要执行,必须先拿到 GIL,可以把 GIL 看作是通行证,并且在一个 Python 进程中,GIL 只有一个。拿不到通行证的线程,就不允许进入 CPU 执行。
**GIL 对多线程的影响:**GIL 对 I/O 绑定的多线程程序的性能没有太大影响,因为在线程等待 I/O 时,锁是在线程之间共享的,而对于受 CPU 限制的程序,如果使用多线程就会受到 GIL 的影响,而且可能会因为锁增加的获取和释放开销会使用掉更多的时间。
因此 Python 多线程适合 I/O 密集的需求(例如爬虫,文件处理,批量 SSH 操作服务器等),而不适合 CPU 密集型的需求 。
**GIL 的解决方法:**使用多进程编程或者换用其他 Python 解释器等等
线程队列返回值 使用队列获取线程返回值
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 import threadingfrom queue import Queuedef job (l, q ): for i in range (len (l)): l[i] = l[i] ** 2 q.put(l) def multithreading (): q = Queue() threads = [] data = [[1 , 2 , 3 ], [3 , 4 , 5 ], [4 , 4 , 4 ], [5 , 5 , 5 ]] for i in range (4 ): t = threading.Thread(target=job, args=(data[i], q)) t.start() threads.append(t) for thread in threads: thread.join() results = [] for _ in range (4 ): results.append(q.get()) print (results) if __name__ == '__main__' : multithreading()
线程同步(线程锁) 如果多个线程共同对某个数据修改,则可能出现不可预料的结果,为了保证数据的正确性,需要对多个线程进行同步,使用 Thread 对象的 Lock 和 Rlock 可以实现简单的线程同步,这两个对象都有 acquire 方法和 release 方法,对于那些需要每次只允许一个线程操作的数据,可以将其操作放到 acquire 和 release 方法之间。如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 import threadingdef job1 (): global A, lock lock.acquire() for _ in range (10 ): A += 1 print ('job1' , A) lock.release() def job2 (): global A, lock lock.acquire() for _ in range (10 ): A += 10 print ('job2' , A) lock.release() if __name__ == '__main__' : lock = threading.Lock() A = 0 t1 = threading.Thread(target=job1) t2 = threading.Thread(target=job2) t1.start() t2.start() t1.join() t2.join() """ 出输出可以看到两种运算并没有交替进行,如果不使用锁,则输出会乱序 job1 1 job1 2 job1 3 job1 4 job1 5 job1 6 job1 7 job1 8 job1 9 job1 10 job2 20 job2 30 job2 40 job2 50 job2 60 job2 70 job2 80 job2 90 job2 100 job2 110 """
限制线程数量 使用threading.Semaphore控制acquire()和release()来控制线程数量
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 import threadingimport timethread_limit = threading.Semaphore(2 ) def thread_job (num:int ) -> None : thread_limit.acquire() time.sleep(2 ) print (num) thread_limit.release() if __name__ == '__main__' : print ("*** Strat ***" ) for i in range (1 , 11 ): time.sleep(0.2 ) t = threading.Thread(target=thread_job, args=(i, ), name="thread" + str (i)) t.start() t.join() print ("*** End ***" )
本文参考链接
Python3 多线程
Python 中异步协程的使用方法介绍
【莫烦Python】Threading 学会多线程 Python
What Is the Python Global Interpreter Lock (GIL)?